Walking around Disneyland with my daughter the other night, I found myself face to face with one of our country’s most intractable taboos.
(Disneyland is still awesome for me, as a kid from 1970s LA. Truly magical.)
If you’re an observer of crowds, one of the more prominent features of the Disneyland crowd is how generally overweight our country has become (I live in the Bay area, and readily admit my interaction with folks on most days is not representative of a broad cross section of our population). I’d estimate at least a third of the folks at Disney are seeing Mike and Molly-level images in the mirror — and about 2–3% or so have more weight than they can carry around, and have therefore graduated to “mobility scooters.”
We’ve seen this debate before — Google refused to call itself a media business for years and years. Now, well…YouTube. And Play. Twitter had similar reluctancies, and now…the NFL (oh, and college softball!). Microsoft tried, but ultimately failed, to be a media company (there’s a reason it’s called MSNBC), and had the sense to retreat from “social media” into “enterprise tools” so as to not beg confusion. Then again, it just bought LinkedIn, so the debate will most certainly flare up (wait, is LinkedIn a media company?!).
Here are the caveats for the rant I am about to write.
The fact that I am writing this on Medium will cause many of you to dismiss me for hypocrisy. Don’t. Read to the end.
I will be saying the word “F*CK” a lot. If that bothers you, time to depart for calmer waters.
This post will be subject to dismissal due to charges of high nostalgia — I will be accused of living in the past, failing to get the future, not getting with the times, being the old man yelling “get off my lawn,” etc. These characterizations will be all entirely right. And totally irrelevant.
This post will be compared, most likely unfavorably, to the many, many, many, many wonderful (and better) posts that have already been written on this subject. That’s fine. I just want to add my voice to the conversation.
This post will piss off friends of mine at Facebook, Medium, LinkedIn, and probably Google. Sorry in advance. Kinda.
This is my 14th annual predictions post. And as I look back on the previous 13 and consider what to write, I’m flooded with uncertainty. That’s not like me. Writing these predictions is something I’ve always looked forward to – I don’t prepare in any demonstrable way, but I do gather crumbs over time, filing them away for the day when I sit down and free associate for however long it takes me to complete this post.
But this time, well, for the first time ever I have very little idea what’s about to come out of the keyboard. Honestly, when I consider the coming 12 months, so much feels up for grabs that I wonder whether it’s wise to prognosticate. Then I remember, it’s all of you reading these words who keep me writing in the first place – your encouragement, your wise (and sometimes cutting) commentary, and your willingness to spend a little time with me and my thoughts. One of my New Year’s resolutions is to write more – it’s always been how I make sense of the world, and this year, the world feels like it needs a lot more sense making. So I’ll be writing at least a few times a week going forward, starting with this uncertain post.
Way back when — well, a few years back anyway— I wrote a series of posts around the idea of “metaservices.” As I mused, I engaged in a bit of derision around the current state (at that point) of the mobile ecosystem, calling it “chiclet-ized” — silos of useful data without a true Internet between them. You know, like individually wrapped cubes of shiny, colored gum that you had to chew one at a time.
I suggested that we needed a connective layer between all those chiclets, letting information flow between all those amazing services.
Much of the Republican debates have been expendable theatrics, but I watched this weekend’s follies from South Carolina anyway. And one thing has struck me: The ads are starting to get better.
This season’s debates have had the highest ratings of any recent Presidential race, and they’re attracting some serious corporate sponsorship. One spot in particular caught my eye:
This ad looks like a lot of others I’ve noticed coming out of large companies these days — dramatic, driving music, compelling fast frame visuals, an overarching sense that something important and world changing is going on.
The spot has one purpose: To make us wonder if a business can be alive. Here’s the ad copy:
Can a business have a mind?
A subconscious.
A power to store every experience, and call upon it through something called intuition.
Can a company have reflexes.
A nervous system.
The ability to react, precisely and correctly, faster than the speed of thought.
Can an enterprise have a sixth sense. A knack for predicting the future.
Can a business have a spirit?
Can a business have a soul?
Can a business be…alive?
THE ANSWER IS SIMPLE. THE ANSWER IS SAP HANA
Given our cultural fascination with evil, AI-driven corporations, I have to wonder how stuff like this gets through any big company’s Fear of Looking Scary filters, right? I mean, does the agency not watch Mr. Robot?
But somehow the spot resonates — if you work in a large company, don’t you want that company to be … alive? Don’t you want it to be fast, and smart, and nimble, and … soulful? Don’t you want to be part of something powerful and vibrant?
Clearly, the ad is working for SAP, they’ve been running it for well over a year, and they (or their agency) felt it was appropriate for the 13+ million folks watching the Republican debates on Saturday night. The ad leaves a pretty clear premise for the viewer: If you want your company to be alive, install our software!
But it begs a larger question: what is the role of corporations in our society going forward, if we’ve begun to accept that they are in fact alive? (And have the rights of people, to boot!)
I’d be curious if folks out there are buying this whole narrative. What do you think?
A couple of weeks ago my wife and I were heading across the San Rafael bridge to downtown Oakland for a show at the Fox Theatre. As all Bay area drivers know, there’s a historically awful stretch of Interstate 80 along that route – a permanent traffic sh*t show. I considered taking San Pablo road, a major thoroughfare which parallels the freeway. But my wife fired up Waze instead, and we proceeded to follow an intricate set of instructions which took us onto frontage roads, side streets, and counter-intuitive detours. Despite our shared unease (unfamiliar streets through some blighted neighborhoods), we trusted the Waze algorithms – and we weren’t alone. In fact, a continuous stream of automobiles snaked along the very same improbable route – and inside the cars ahead and behind me, I saw glowing blue screens delivering similar instructions to the drivers within.
I double took upon arriving at Medium just now, fingers flexed to write about semi-private data and hotel rooms (trust me, it’s gonna be great).
But upon my arrival, I was greeted thusly:
Now, I have no categorical beef with Facebook, I understand the value of its network as much as the next publisher. But it always struck me that Medium was forging a third way — it’s not a blogging platform, quite, at least as we used to understand them. And it’s not a social network, though it has a social feel. It’s something … of itself, and that’s a good thing.
President Obama’s final State of the Union address is currently trending on Medium, which is pretty much what you might expect given Medium is where the White House decided to release it (take that, Facebook! — though a piece about building Instagram has about twice as many recommendations, but I digress…).
I watched the speech last night while at a company retreat with 18 of my colleagues from NewCo. Over and over, the President hit on trends consistent with our thesis of fundamental change in business and culture. For example, he spoke of decoupling benefits such as healthcare from employers, because in the NewCo era, people move between jobs a lot more (or are self employed, or want to leap into a startup). Obama spoke of living in a time of extraordinary technological and social change, of a deepening and troubling social inequality, of optimism and hard work and a right to thrive in “this new economy.”
I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.
That link opened the LinkedIn app on my phone. In the fellow’s LI feed was another link, this one to a tweet he had mentioned in his feed. The tweet happened to be from a person I know, so I clicked on it, and the Twitter app opened on my phone. I read the tweet, then pressed the back button and….








 I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.
I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.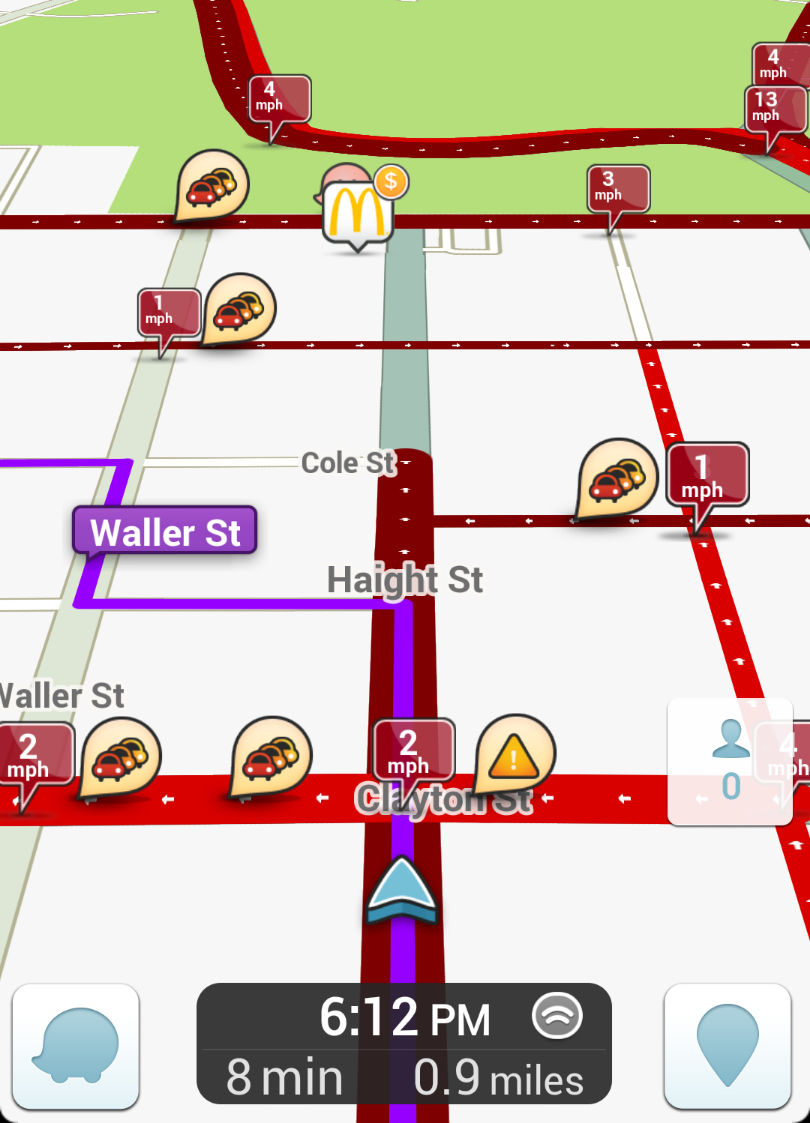{kind=link}