Thanks to NewCo, I’ve gotten out of the Bay Area bubble and visited more than a dozen major cities across several continents in the past year. I’ve met with founders inside hundreds of mission-driven companies, in cities as diverse as Istanbul, Boulder, Cincinnati, and Mexico City. I’ve learned about the change these companies are making in the world, and I’ve compared notes with the leaders of large, established companies, many of which are the targets of that change.
As I reflect on my travels, a few consistent themes emerge:
Much of the Republican debates have been expendable theatrics, but I watched this weekend’s follies from South Carolina anyway. And one thing has struck me: The ads are starting to get better.
This season’s debates have had the highest ratings of any recent Presidential race, and they’re attracting some serious corporate sponsorship. One spot in particular caught my eye:
This ad looks like a lot of others I’ve noticed coming out of large companies these days — dramatic, driving music, compelling fast frame visuals, an overarching sense that something important and world changing is going on.
The spot has one purpose: To make us wonder if a business can be alive. Here’s the ad copy:
Can a business have a mind?
A subconscious.
A power to store every experience, and call upon it through something called intuition.
Can a company have reflexes.
A nervous system.
The ability to react, precisely and correctly, faster than the speed of thought.
Can an enterprise have a sixth sense. A knack for predicting the future.
Can a business have a spirit?
Can a business have a soul?
Can a business be…alive?
THE ANSWER IS SIMPLE. THE ANSWER IS SAP HANA
Given our cultural fascination with evil, AI-driven corporations, I have to wonder how stuff like this gets through any big company’s Fear of Looking Scary filters, right? I mean, does the agency not watch Mr. Robot?
But somehow the spot resonates — if you work in a large company, don’t you want that company to be … alive? Don’t you want it to be fast, and smart, and nimble, and … soulful? Don’t you want to be part of something powerful and vibrant?
Clearly, the ad is working for SAP, they’ve been running it for well over a year, and they (or their agency) felt it was appropriate for the 13+ million folks watching the Republican debates on Saturday night. The ad leaves a pretty clear premise for the viewer: If you want your company to be alive, install our software!
But it begs a larger question: what is the role of corporations in our society going forward, if we’ve begun to accept that they are in fact alive? (And have the rights of people, to boot!)
I’d be curious if folks out there are buying this whole narrative. What do you think?
A couple of weeks ago my wife and I were heading across the San Rafael bridge to downtown Oakland for a show at the Fox Theatre. As all Bay area drivers know, there’s a historically awful stretch of Interstate 80 along that route – a permanent traffic sh*t show. I considered taking San Pablo road, a major thoroughfare which parallels the freeway. But my wife fired up Waze instead, and we proceeded to follow an intricate set of instructions which took us onto frontage roads, side streets, and counter-intuitive detours. Despite our shared unease (unfamiliar streets through some blighted neighborhoods), we trusted the Waze algorithms – and we weren’t alone. In fact, a continuous stream of automobiles snaked along the very same improbable route – and inside the cars ahead and behind me, I saw glowing blue screens delivering similar instructions to the drivers within.
I double took upon arriving at Medium just now, fingers flexed to write about semi-private data and hotel rooms (trust me, it’s gonna be great).
But upon my arrival, I was greeted thusly:
Now, I have no categorical beef with Facebook, I understand the value of its network as much as the next publisher. But it always struck me that Medium was forging a third way — it’s not a blogging platform, quite, at least as we used to understand them. And it’s not a social network, though it has a social feel. It’s something … of itself, and that’s a good thing.
President Obama’s final State of the Union address is currently trending on Medium, which is pretty much what you might expect given Medium is where the White House decided to release it (take that, Facebook! — though a piece about building Instagram has about twice as many recommendations, but I digress…).
I watched the speech last night while at a company retreat with 18 of my colleagues from NewCo. Over and over, the President hit on trends consistent with our thesis of fundamental change in business and culture. For example, he spoke of decoupling benefits such as healthcare from employers, because in the NewCo era, people move between jobs a lot more (or are self employed, or want to leap into a startup). Obama spoke of living in a time of extraordinary technological and social change, of a deepening and troubling social inequality, of optimism and hard work and a right to thrive in “this new economy.”
I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.
That link opened the LinkedIn app on my phone. In the fellow’s LI feed was another link, this one to a tweet he had mentioned in his feed. The tweet happened to be from a person I know, so I clicked on it, and the Twitter app opened on my phone. I read the tweet, then pressed the back button and….
Way back in 2012 – four years ago in real time, three decades or so in Internet time – I predicted that Facebook would build an alternative to Google’s AdSense based on its extraordinary data set. I was right, but…off by a few years. From Ad Exchanger:
AdExchanger has learned Facebook Audience Network is one month into a test involving about 10 publishers that would see the ad network’s placements run on mobile web pages. The expansion brings its own set of technical hurdles, along with a large revenue expansion opportunity for Audience Network, which reached a $1 billion run rate last quarter.
…A Facebook rep confirmed the test and Diply’s involvement, but declined further comment.
Once upon a time, I’d read the yearly lists of “best albums” from folks like Rick Webb or Marc Ruxin, and immediately head over to the iTunes store for a music-buying binge. Afterwards, I’d listen happily to my new music for days on end, forging new connections between the bands my pals had suggested and my own life experiences. It usually took three to four full album plays to appreciate the new band and set its meanings inside my head, but once there, I could call those bands up in context and apply them to the right mood or circumstance. Over years of this, I built a web of musical taste that’s pretty intricate, if difficult to outwardly describe.
About two years ago, I started paying for Spotify. Because I’d paid for “all you can eat” music, I never had to pay for a particular band’s work. Ever since, my musical experience has become…far less satisfying.
Intrigued (well done, Mr. Rosoff), I clicked the link, noting it was to Business Insider, a publication for which I have decidedly complicated feelings**. In any case, the story was great, if single sourced. A reporter wandering the halls at CES found a desultory Accenture booth, manned by one Charles Hartley, a “company representative.” A quick Google search (done by me, but I digress), tells us Mr. Hartley is a PR executive focused on analysts and global media — an appropriate resume for manning a booth at CES, to be sure.




 I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.
I just opened an email on my phone. It was from a fellow I don’t know, inviting me to an event I’d never heard of. Intrigued, I clicked on the fellow’s LinkedIn, which was part of his email signature.

 Finishing up my reading for the evening, I came across
Finishing up my reading for the evening, I came across 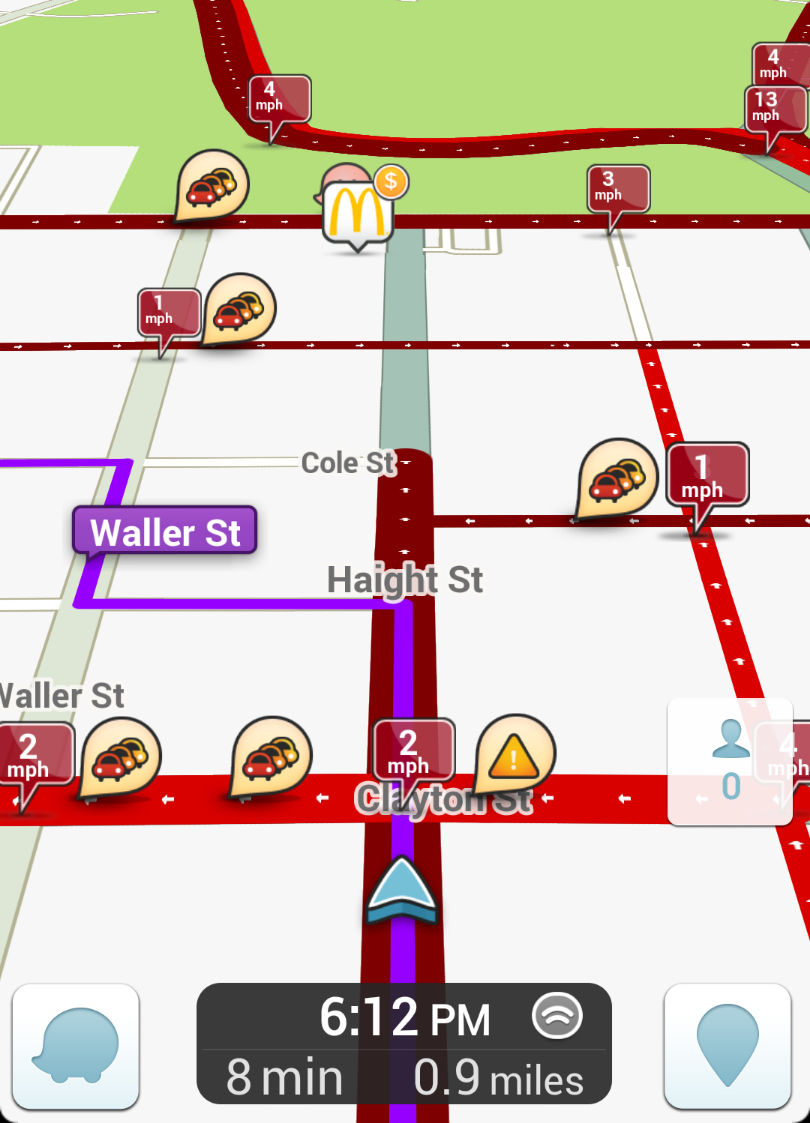{kind=link}