
God, “innovation.” First banalized by undereducated entrepreneurs in the oughts, then ground to pablum by corporate grammarians over the past decade, “innovation” – at least when applied to business – deserves an unheralded etymological death.
But.
This will be a post about innovation. However, whenever I feel the need to peck that insipid word into my keyboard, I’m going to use some variant of the verb “to flourish” instead. Blame Nobel laureate Edmund Phelps for this: I recently read his Mass Flourishing, which outlines the decline of western capitalism, and I find its titular terminology far less annoying.

So flourishing it will be.
In his 2013 work, Phelps (who received the 2006 Nobel in economics) credits mass participation in a process of innovation (sorry, there’s that word again) as central to mass flourishing, and further argues – with plenty of economic statistics to back him up – that it’s been more than a full generation since we’ve seen mass flourishing in any society. He writes:
…prosperity on a national scale—mass flourishing—comes from broad involvement of people in the processes of innovation: the conception, development, and spread of new methods and products—indigenous innovation down to the grassroots. This dynamism may be narrowed or weakened by institutions arising from imperfect understanding or competing objectives. But institutions alone cannot create it. Broad dynamism must be fueled by the right values and not too diluted by other values.
Phelps argues the last “mass flourishing” economy was the 1960s in the United States (with a brief but doomed resurgence during the first years of the open web…but that promise went unfulfilled). And he warns that “nations unaware of how their prosperity is generated may take steps that cost them much of their dynamism.” Phelps further warns of a new kind of corporatism, a “techno nationalism” that blends state actors with corporate interests eager to collude with the state to cement market advantage (think Double Irish with a Dutch Sandwich).
These warnings were proffered largely before our current debate about the role of the tech giants now so dominant in our society. But it sets an interesting context and raises important questions. What happens, for instance, when large corporations capture the regulatory framework of a nation and lock in their current market dominance (and, in the case of Big Tech, their policies around data use?).
I began this post with Phelps to make a point: The rise of massive data monopolies in nearly every aspect of our society is not only choking off shared prosperity, it’s also blinkered our shared vision for the kind of future we could possibly inhabit, if only we architect our society to enable it. But to imagine a different kind of future, we first have to examine the present we inhabit.
The Social Architecture of Data
I use the term “architecture” intentionally, it’s been front of mind for several reasons. Perhaps the most difficult thing for any society to do is to share a vision of the future, one that a majority might agree upon. Envisioning the future of a complex living system – a city, a corporation, a nation – is challenging work, work we usually outsource to trusted institutions like government, religions, or McKinsey (half joking…).
But in the past few decades, something has changed when it comes to society’s future vision. Digital technology became synonymous with “the future,” and along the way, we outsourced that future to the most successful corporations creating digital technology. Everything of value in our society is being transformed into data, and extraordinary corporations have risen which refine that data into insight, knowledge, and ultimately economic power. Driven as they are by this core commodity of data, these companies have acted to cement their control over it.
This is not unusual economic behavior, in fact, it’s quite predictable. So predictable, in fact, that it’s developed its own structure – an architecture, if you will, of how data is managed in today’s information society. I’ve a hypothesis about this architecture – unproven at this point (as all are) – but one I strongly suspect is accurate. Here’s how it might look on a whiteboard:
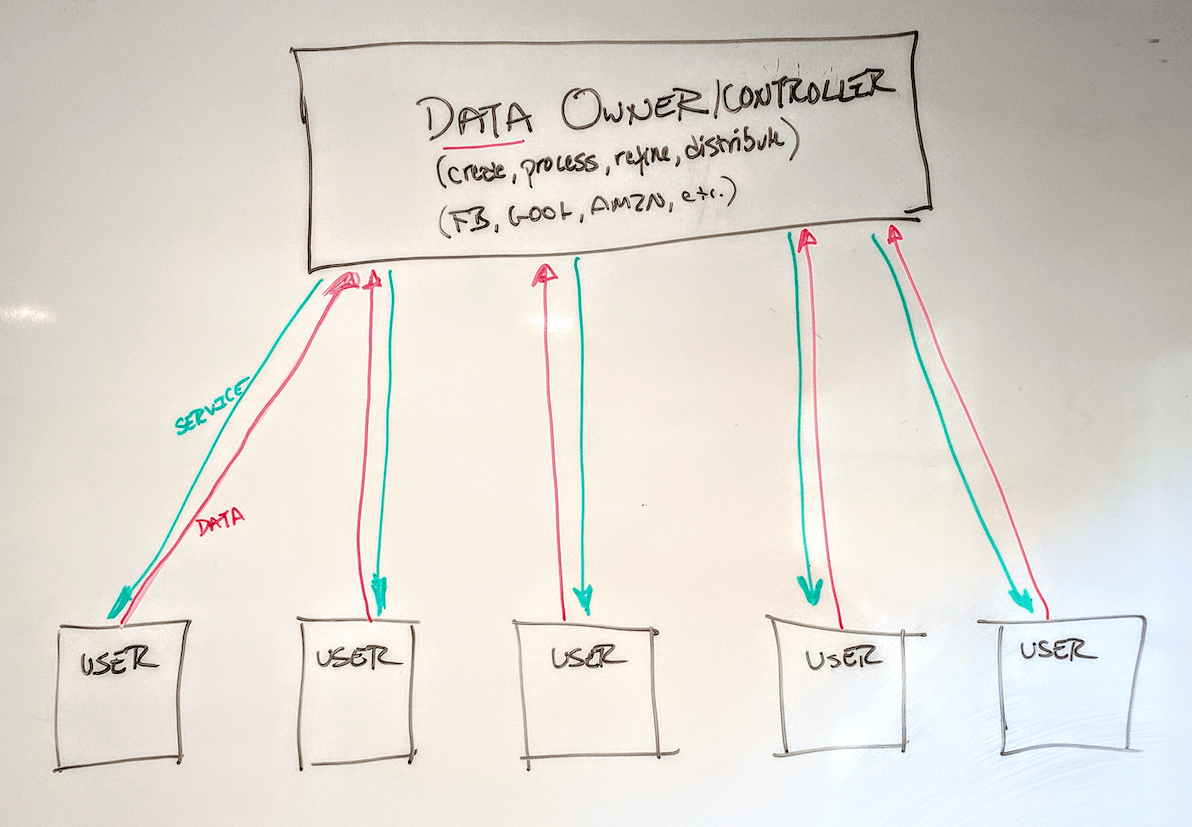
We “users” deliver raw data to a service provider, like Facebook or Google, which then captures, refines, processes, and delivers that data back as services to us. The social contract we make is captured in these services’ Terms of Services – we may “own” the data, but for all intents and purposes, the power over that information rests with the platform. The user doesn’t have a lot of creative license to do much with that data he or she “owns” – it lives on the platform, and the platform controls what can be done with it.
Now, if this sounds familiar, you’re likely a student of early computing architectures. Back before the PC revolution, most data, refined or not, lived on a centralized platform known as a mainframe. Nearly all data storage and compute processing occurred on the mainframe. Applications and services were broadcast from the mainframe back to “dumb terminals,” in front of which early knowledge workers toiled. Here’s a graph of that early mainframe architecture:

This mainframe architecture had many drawbacks – a central point of failure chief among them, but perhaps its most damning characteristic was its hierarchical, top down architecture. From an user’s point of view, all the power resided at the center. This was great if you ran IT at a large corporation, but suffice to say the mainframe architecture didn’t encourage creativity or a flourishing culture.
The mainframe architecture was supplanted over time with a “client server” architecture, where processing power migrated from the center to the edge, or node. This was due in large part to the rise the networked personal computer (servers were used for storing services or databases of information too large to fit on PCs). Because they put processing power and data storage into the hands of the user, PCs became synonymous with a massive increase in productivity and creativity (Steve Jobs called them “bicycles for the mind.”) With the PC revolution power transferred from the “platform” to the user – a major architectural shift.
The rise of networked personal computers became the seedbed for the world wide web, which had its own revolutionary architecture. I won’t trace it here (many good books exist on the topic), but suffice to say the core principle of the early web’s architecture was its distributed nature. Data was packetized and distributed independent of where (or how) it might be processed. As more and more “web servers” came online, each capable of processing data as well as distributing it, the web became a tangled, hot mess of interoperable computing resources. What mattered wasn’t the pipes or the journey of the data, but the service created or experienced by the user at the point of that service delivery, which in the early days was of course a browser window (later on, those points of delivery became smartphone apps and more).
If you were to attempt to map the social architecture of data in the early web, your map would look a lot like the night sky – hundreds of millions of dots scattered in various constellations across the sky, each representing a node where data might be shared, processed, and distributed. In those early days the ethos of the web was that data should be widely shared between consenting parties so it might be “mixed and mashed” so as to create new products and services. There was no “mainframe in the sky” anymore – it seemed everyone on the web had equal and open opportunities to create and exchange value.
This is why the late 1990s through mid oughts were a heady time in the web world – nearly any idea could be tried out, and as the web evolved into a more robust set of standards, one could be forgiven for presuming that the open, distributed nature of the web would inform its essential social architecture.
But as web-based companies began to understand the true value of controlling vast amounts of data, that dream began to fade. As we grew addicted to some of the most revelatory web services – first Google search, then Amazon commerce, then Facebook’s social dopamine – those companies began to centralize their data and processing policies, to the point where we are now: Fearing these giants’ power over us, even as we love their products and services.
An Argument for Mass Flourishing
So where does that leave us if we wish to heed the concerns of Professor Phelps? Well, let’s not forget his admonition: “nations unaware of how their prosperity is generated may take steps that cost them much of their dynamism.” My hypothesis is simply this: Adopting a mainframe architecture for our most important data – our intentions (Google), our purchases (Amazon), our communications and social relationships (Facebook) – is not only insane, it’s also massively deprecative of future innovation (damn, sorry, but sometimes the word fits). In Facebook, Tear Down This Wall, I argued:
… it’s impossible for one company to fabricate reality for billions of individuals independent of the interconnected experiences and relationships that exist outside of that fabricated reality. It’s an utterly brittle product model, and it’s doomed to fail. Banning third party agents from engaging with Facebook’s platform insures that the only information that will inform Facebook will be derived from and/or controlled by Facebook itself. That kind of ecosystem will ultimately collapse on itself. No single entity can manage such complexity. It presumes a God complex.
So what might be a better architecture? I hinted at it in the same post:
Facebook should commit itself to being an open and neutral platform for the exchange of value across not only its own services, but every service in the world.
In other words, free the data, and let the user decide what do to with it. I know how utterly ridiculous this sounds, in particular to anyone reading from Facebook proper, but I am convinced that this is the only architecture for data that will allow a massively flourishing society.
Now this concept has its own terminology: Data portability. And this very concept is enshrined in the EU’s GDPR legislation, which took effect one week ago. However, there’s data portability, and then there’s flourishing data portability – and the difference between the two really matters. The GDPR applies only to data that a user *gives* to a service, not data *co-created* with that service. You also can’t gather any insights the service may have inferred about you based on the data you either gave or co-created with it. Not to mention, none of that data is exported in a machine readable fashion, essentially limiting its utility.

But imagine if that weren’t the case. Imagine instead you can download your own Facebook or Amazon “token,” a magic data coin containing not only all the useful data and insights about you, but a control panel that allows you to set and revoke permissions around that data for any context. You might pass your Amazon token to Walmart, set its permissions to “view purchase history” and ask Walmart to determine how much money it might have saved you had you purchased those items on Walmart’s service instead of Amazon. You might pass your Facebook token to Google, set the permissions to compare your social graph with others across Google’s network, and then ask Google to show you search results based on your social relationships. You might pass your Google token to a startup that already has your genome and your health history, and ask it to munge the two in case your 20-year history of searching might infer some insights into your health outcomes.
This might seem like a parlor game, but this is the kind of parlor game that could unleash an explosion of new use cases for data, new startups, new jobs, and new economic value. Tokens would (and must) have privacy, auditing, trust, value exchange, and the like built in (I tried to write this entire post without mentioned blockchain, but there, I just did it), but presuming they did, imagine what might be built if we truly set the data free, and instead of outsourcing its power and control to massive platforms, we took that power and control and, just like we did with the PC and the web, pushed it to the edge, to the node…to ourselves?
I rather like the sound of that, and I suspect Mssr. Phelps would as well. Now, how might we get there? I’ve no idea, but exploring possible paths certainly sounds like an interesting project…
Years ago I recall seeing a huge historical wall chart outlining the bell-curve swings in East-West power shifts occurring over +200/400 year cycles.
Simply put I would tell Mr. Phelps, ‘You can’t be top dog forever!’
I suspect companies like Google, Facebook, Amazon and all the other usual suspects will continue efforts to stay relevant over the coming years. But they can’t be top dog forever either. (IBM, General Electric, Westinghouse…)
Having been a musician in another life, I keep an old radio/cassette player handy. I don’t have to give it my name. I don’t have to type in a password. I plug it in, pop-in a tape and turn it on.